O suicídio e a prevenção dele tem sido um tema tratado com extrema atenção, já que estatisticamente tem ocorrido um aumento considerável a cada ano. Segundo uma especialista nessa área, dois terços das pessoas que cometeram suicídio comunicaram claramente essa intenção a parentes próximos ou amigos. O meio virtual tem sido umas das formas de expressar os sentimentos e pensamentos de forma pública com pessoas que possuem interesses em comum. Este trabalho propõe uma técnica supervisionada para detecção de ideações suicidas em textos postados na WEB, utilizando a abordagem de representação distribuída de parágrafo alheada a um algoritmo de classificação.
AUTORES:
Elizangela de Freitas dos Santos 2
Luiz Fernando S. Serique Junior 2
Artigo publicado na Revista Info | Vol 1
Introdução
Segundo dados estatísticos da Organização Pan-Americana de Saúde/ Organização Mundial da Saúde, a cada 40 segundos, uma pessoa se suicida no mundo[1]. A cada ano cerca de 800 mil pessoas cometem suicídio, e a quantidade de tentativas supera esse número. O suicídio pode ocorrer em qualquer idade, porém, esta foi a segunda principal causa de morte entre jovens de 15 a 29 anos em todo o mundo no ano de 2015. Cerca de 78% dos suicídios no mundo ocorrem em países de baixa e média renda [2]. No Brasil, o suicídio é a quarta maior causa de morte, sendo contabilizadas em média 11 mil por ano [3].
Para a Mônica Medeiros Kother Macedo, psicanalista especializada em suicídio e professora da PUCRS, dois terços dos que cometem suicídio comunicaram claramente essa intenção a parentes próximos ou amigos [4]. Sendo assim, é necessário ficar atento às frases de alerta, pois por trás delas estão os sentimentos de pessoas com ideações suicidas [5]. “A ideação suicida se refere a pensamentos de se matar ou planejar suicídio, enquanto o comportamento suicida é frequentemente definido para incluir todos os possíveis atos de autoflagelação com a intenção de causar a morte”. A vigilância e monitoramento de tentativas de suicídio e tendências autodestrutivas são as principais formas de prevenção do suicídio-[6].
Atualmente existem meios de comunicação virtuais que permitem expressar
pensamentos, sentimentos e opiniões de forma pública com pessoas que possuem
interesses em comum, e a internet tem viabilizado a expansão desse processo.
Dessa forma, ideações suicidas e tendências autodestrutivas podem ser expressas
como forma de pedido de ajuda, o que pode facilitar a identificação de
possíveis casos futuros de suicídio,
e, por consequência, sua prevenção.
As emoções têm sido objeto de pesquisa em diversas áreas de estudos, inclusive na ciência da computação, o que tem atraído a atenção dos pesquisadores interessados no processamento de textos, recuperação de informação e na interação humano-computador [7]. Nesse contexto, umas das áreas de maior relevância é a mineração de texto, que se utiliza da aplicação de algoritmos aos documentos de textos com o objetivo de obter conhecimento.
Este trabalho teve como objetivo a prevenção de suicídios, utilizando a representação distribuída de parágrafo para o pré-processamento prévio de textos coletados na web, juntamente com um algoritmo de classificação, a fim de identificar ideações suicidas.
Trabalhos relacionados
Em [6] é abordada a prevenção do suicídio utilizando técnicas de aprendizado de máquina para detecção de ideações suicidas em mídias sociais, onde foi realizada análise dos conteúdos postados pelos usuários de redes sociais para sinalizar se tais eram preocupantes ou não. As principais contribuições deste artigo foram:
1. Criação de um conjunto de dados rotulados para aprendizado de padrões em tweets, exibindo ideação suicida por anotação manual;
2. Apresentação de um conjunto de recursos para alimentar os classificadores com a intenção de melhorar o desempenho dos algoritmos de aprendizagem de máquina;
3. Emprego de quatro classificadores binários no conjunto de dados para comparação dos resultados obtidos utilizando abordagens variadas para validar a metodologia que foi proposta. A Tabela 1 apresenta os referidos classificados com suas respectivas métricas. O modelo gerado a partir do algoritmo Random Forest obteve o melhor resultado.
| Modelo | Acurácia | Precisão | Recall | F1 Score |
| Regressão Logística | 0,830 | 0,819 | 0,850 | 0,832 |
| Random Forest | 0,858 | 0,842 | 0,846 | 0,844 |
| Gradient Boosting Decision Tree | 0,805 | 0,802 | 0,820 | 0,807 |
| XGBoost | 0,817 | 0,831 | 0,800 | 0,812 |
Tabela 1 – Resultados dos Classificadores – Fonte SAWHNEY, et. al. (2018)
No artigo [8] é proposto o algoritmo Doc2Vec, um algoritmo não supervisionado que aprende representações contínuas de vetores distribuídos para partes de textos de tamanho variável, que podem diversificar de sentenças a documentos. Nesse a representação vetorial foi treinada para ser útil na previsão de palavras em um parágrafo.
- Algoritmos
Neste trabalho será utilizado o algoritmo de representação vetorial de parágrafos Doc2Vec, porém, para melhor entendimento, faz-se necessária uma explanação da representação vetorial de palavras. Esta seção é destinada ao detalhamento de ambos.
- Representação vetorial de palavras
Em [8] é realizada uma abordagem sobre o algoritmo para representação vetorial de palavras, conhecido como Word2Vec, que tem como técnica a rede neural. Esse modelo fornece duas arquiteturas, sendo elas fundamentadas em Bag-of-Words, que tem por objetivo prever a probabilidade de um termo ocorrer, baseado em uma janela de palavras próximas e o Skip-Gram, que visa predizer de forma maximizada quais termos ocorrem próximas a um determinado termo[9].
Segundo [9] essa abordagem, consegue-se obter aspectos semânticos e sintáticos com uma granularidade fina utilizando operações aritméticas de vetores simples. Nessa estrutura, cada palavra é mapeada para um único vetor, representado por uma coluna em uma matriz W. A coluna é indexada pela posição da palavra no vocabulário. A junção ou soma dos vetores é usada para prever a próxima palavra em uma sentença, ou seja, dada uma sequência de palavras de treinamento w1, w2, w3, …, wT, o objetivo do modelo vetorial de palavras é maximizar a probabilidade da predição. A
Figura 1 mostra uma estrutura para aprendizado de vetores de palavras, onde um contexto de três palavras (“the”, “cat” e “sat”) é usado para prever a quarta palavra (“on”). As palavras de entrada são mapeadas para colunas da matriz W para predição da palavra de saída.
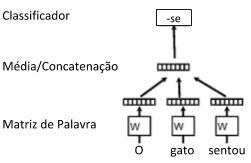
Figura 1- Representação Vetorial de Palavras (Tradução Livre) – Fonte: Le e Mikolov (2014)
- Representação vetorial de parágrafos
No artigo [8] é proposto um modelo de memória distribuída, chamado Doc2Vec, em que a abordagem de vetor de parágrafos é baseada no aprendizado de vetores de palavras, que foi discutido no tópico anterior. Esses vetores de palavras contribuem na predição da próxima palavra da sentença e podem eventualmente capturar a semântica como um resultado indireto na tarefa da predição. Os vetores de parágrafo também são solicitados a contribuir para a tarefa de previsão da próxima palavra, considerando muitos contextos amostrados no parágrafo. Nesse método, os vetores de palavras e parágrafos são calculados de forma a prever a próxima palavra em um contexto.
Na representação distribuída de parágrafo, é definido um token de parágrafo, que pode ser considerado como outra palavra. Ele age como uma memória que lembra o que está faltando no contexto atual – ou o tópico do parágrafo. Por esse motivo, frequentemente esse modelo é chamado de Modelo de Memória Distribuída de Vetores de Parágrafo (PV-DM).
A Figura 2 apresenta a estrutura de aprendizado de vetor de parágrafos, em que mostra a semelhança com o aprendizado do vetor de palavras. A única mudança é o token de parágrafo adicional que é mapeado para um vetor via matriz “D”. Nesse modelo, a concatenação ou média desse vetor com um contexto de três palavras é usada para prever a quarta palavra. O vetor de parágrafo representa a informação que falta do contexto atual e pode atuar como uma memória do tópico do parágrafo.
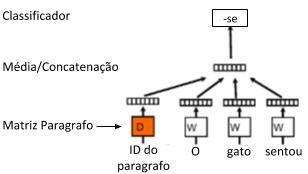
Figura 2 – Representação Vetorial de Parágrafos (Tradução Livre) – Fonte: Le e Mikolov (2014)
- Metodologia
A mineração de texto é considerada um processo de descoberta de conhecimento em textos, que tem por objetivo a extração de informações relevantes a partir de coleções de texto dos mais variados tipos. [10]. Nessa é envolvida a aplicação de algoritmos computacionais que processam e identificam informações úteis, mas que estão implícitas e que provavelmente não poderiam ser descobertas fazendo uso de métodos convencionais, como a consulta, pois estes em geral estão armazenados em formato não estruturado [11].
Na mineração de texto são definidas etapas que visam auxiliar no processo de descoberta de conhecimento a partir de bases de dados textuais. Neste trabalho será utilizado o modelo proposto por [12], em que suas etapas são apresentadas na Figura 3.

Figura 3 -Etapas do Processo de Mineração de Texto – Fonte: Adaptada de Aranha (2007).
O objetivo desta seção é apresentar todas as fases e técnicas consideradas neste trabalho. A etapa de indexação não foi utilizada, pois não houve a necessidade de extração de conceitos documentais através da análise do conteúdo e tradução da linguagem em termos de indexação, que é o objetivo desta etapa [7].
- Coleta
A coleta de dados com ideações suicidas tradicionalmente é um processo difícil, já que existe um grande estigma social em relação a esse assunto, porém, é crescente o número de pessoas que têm utilizado a internet para desabafar, buscar ajuda e discutir questões de saúde mental [6].
Neste trabalho, a extração de dados foi realizada de forma manual. Foram geradas duas bases de dados: com textos que continham ideações suicidas e outra com textos que não continham ideações suicidas. Para a base de dados com ideações suicidas, a coleta foi baseada em estudos científicos[6][13] que identificaram frases que demonstravam esse aspecto, em que os textos foram analisados por humanos cientes de aspectos da psicologia cognitiva. A partir disso e em adição aos registros já coletados, foram retirados textos dos seguintes locais:
- Um blog [18] em que seus usuários expressavam pensamentos de acabar com a própria vida;
- Relatos de pessoas que deixaram cartas de despedida, mensagem escrita ou falada antes de cometer o ato do suicídio [19][20][21][22].
A formação da base de dados com textos que não continham ideações suicidas foi realizada a partir de textos retirados de blogs, que continham frases que expressavam felicidade e motivação [23][24][25]. Ao todo, foram obtidos 428 registros: 214 com ideações suicidas e 214 sem ideação suicida.
- Pré-Processamento
A etapa de pré-processamento foi realizada após a etapa da coleta dos dados. Essa teve por objetivo o aumento da qualidade dos dados, em que diversas técnicas foram aplicadas e até mesmo combinadas através do Processamento de Linguagem Natural (PLN). Em [14] é definido o PLN como qualquer tipo de manipulação computacional de linguagens naturais, como, por exemplo, a língua portuguesa.
Nessa etapa foram realizadas tarefas para que os documentos textuais fossem transformados em um formato estruturado para posterior aplicação dos algoritmos de aprendizagem de máquina. Neste trabalho as tarefas foram realizadas com o auxílio da biblioteca de código aberto chamada Natural Language Toolkit (NLTK)[14], desenvolvida para a linguagem de programação Python. As tarefas utilizadas neste trabalho foram:
- Normalização dos Dados, que teve por finalidade a remoção de acentos e transformação de todas as palavras em minúsculas.
- Tokenization(Atomização), que teve por objetivo extrair unidades mínimas do texto, chamadas tokens, que na maioria das vezes corresponde a uma palavra do texto, podendo também estar relacionado a mais de uma palavra, símbolo ou caractere de pontuação. Nessa tarefa somente as palavras foram consideradas.
- Remoção de Stopwords: Existem muitos tokens que podem aparecer de forma frequente em um documento, mas que não possuem nenhum valor semântico e não ajudam na distinção do significado dos textos. Tais tokens são chamados de Stopwords. Os Stopwords podem corresponder a artigos, preposições, pontuações, conjunções e pronomes. Para este trabalho foi utilizada uma Stoplist, fornecida pela NLTK, que é uma lista de palavras definidas como Stopwords a serem removidas durante essa tarefa no pré-processamento.
- Stemming: O processo de Stemming consistiu em reduzir uma palavra ao seu radical. Nessa tarefa, os sufixos das palavras que indicam variação na forma da palavra como plural e tempos verbais foram removidos[15]. Para esse fim, foi utilizado o algoritmo RSLP (Removedor de Sufixos da Língua Portuguesa), que é um algoritmo de remoção de sufixos para o português [16]. O RSLP é composto de 8 etapas que precisam ser executadas em uma ordem definida. A Figura 3 apresenta a sequência de etapas de Stemming.
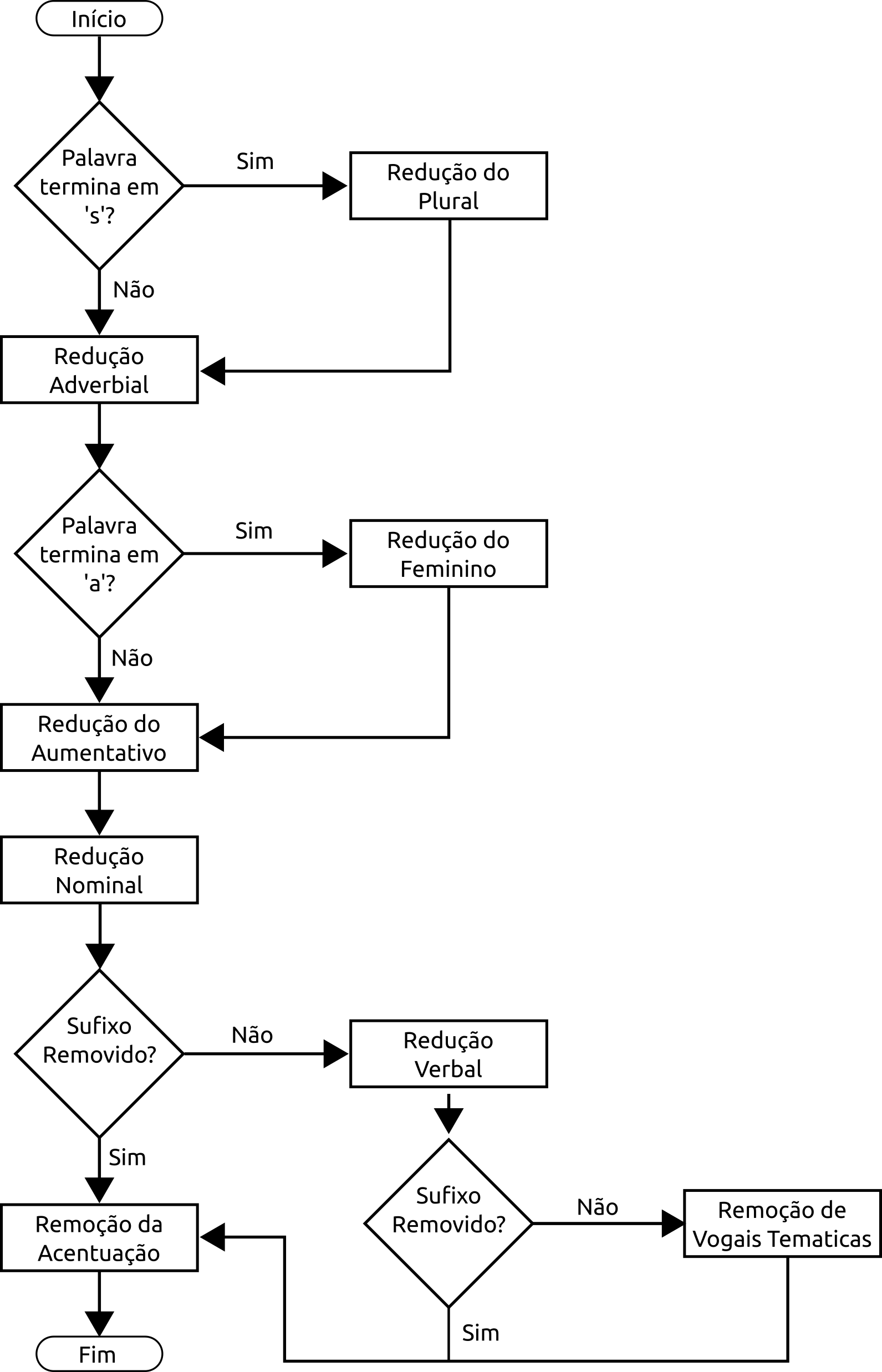
Figura 4 – Etapas do Algoritmo RSLP – Fonte: Adaptada de COELHO (2007)
A Tabela 2 apresenta a frase “Não quero mais estar vivo”, que passou por todas as etapas do pré-processamento de textos, na mesma ordem descrita.
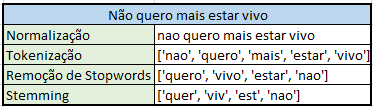
Tabela 2 – Frase Pré-Processada
- Mineração
Esta seção tem como finalidade apresentar as tarefas da mineração de textos definidas para cumprimento dos objetivos determinados para este
trabalho. É através dessa que ocorre a descoberta do conhecimento esperado.
A etapa de mineração dos dados consiste no aprendizado de máquina, em que ocorre a construção de um modelo a partir do algoritmo escolhido. Essa contempla o treinamento e validação do modelo gerado. O treinamento consiste em apresentar ao algoritmo classificador rótulos que o faz aprender sobre os dados que se quer analisar. Por outro lado, a etapa de teste consiste em validar o modelo gerado na etapa de treinamento. Essa última etapa será descrita na próxima seção.
Para a realização do treinamento e teste, foi necessário dividir a base de dados em duas partes. Para esse fim, existem algumas estratégias, e uma delas será apresentada neste trabalho, a Holdout, que consiste em separar uma porcentagem do conjunto de dados que será destinado ao treinamento e outro conjunto de dados destinado ao teste. Para este trabalho foi utilizado 75% dos dados para o treinamento e 25% para o teste. A Figura 4 apresenta a estratégia Holdout.
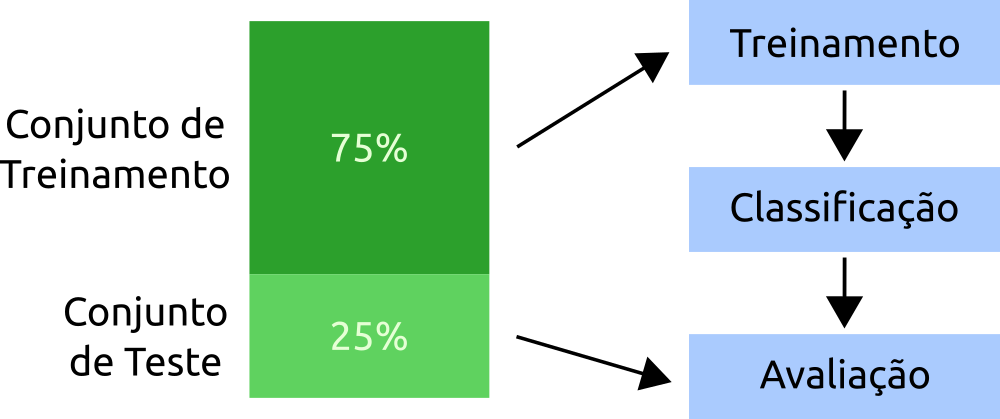
Figura 5 – Estratégia holdout para treinamento e validação
do classificador
Na construção do
modelo, foi utilizada a implementação Doc2Vec,disponível na biblioteca de modelagem
semântica de textos Gensim [26] para criação da representação vetorial
distribuída de parágrafos. Para esse algoritmo foram configurados alguns
parâmetros com o objetivo de obter um bom resultado. O número de interações
sobre o corpus foi representado pelo parâmetro “max_epochs”. A dimensionalidade dos vetores foi definida pelo
parâmetro “vector_size”. O parâmetro
que se refere à taxa inicial de aprendizado é o “alpha”. A diminuição linear da
taxa de aprendizado foi definida pelo parâmetro “min_alpha”, esta ocorre na medida que o treinamento progride. A
quantidade mínima de termos frequentes a serem desconsiderados foi representado
pelo parâmetro “min_count”. O
parâmetro “dm” foi utilizado para a
definição da distribuição da memória no treinamento. A distância máxima entre a
palavra atual e a prevista dentro de uma sentença foi definida pelo parâmetro
“window”, e para este foi utilizado o valor padrão da ferramenta. A Tabela 3 apresenta os valores definidos
para cada parâmetro descrito acima. Esstes foram definidos de forma
empírica.
| PARÂMETROS | VALORES |
| max_epochs | 1000 |
| vector_size | 500 |
| Alpha | 0.01 |
| min_alpha | 0.00025 |
| min_count | 1 |
| Dm | 1 |
| Window | 5 |
Tabela 3 – Valores dos parâmetros definidos para o Doc2Vec
Na realização da classificação dos textos em “Suicidas” e “Não Suicidas” foi utilizado o algoritmo classificador de Regressão Logística através do pacote de aprendizado de máquina Scikit-learn[17]. Para os valores dos parâmetros não foram alterados, sendo utilizados os padrões da ferramenta.
- Avaliação
Esta seção é destinada à análise dos resultados alcançados nas seções anteriores, onde foi realizado o processo de mineração de textos para identificação de textos com ideações suicidas.
- Análise Algoritmo de Classificação
Essa etapa consistiu em validar o modelo gerado na seção anterior, onde foram utilizados os 25% dos dados destinados a esse fim.
Para a validação do classificador, foram utilizadas duas métricas: Receiver Operating Characteristics (ROC) e Area Under the Curve (AUC), conforme ilustrado na Figura 6.
Foi verificado o resultado da classificação do modelo gerado a partir do algoritmo Doc2Vec juntamente com o de Regressão Logística, e o mesmo apresentou um valor de AUC igual a 0.82.
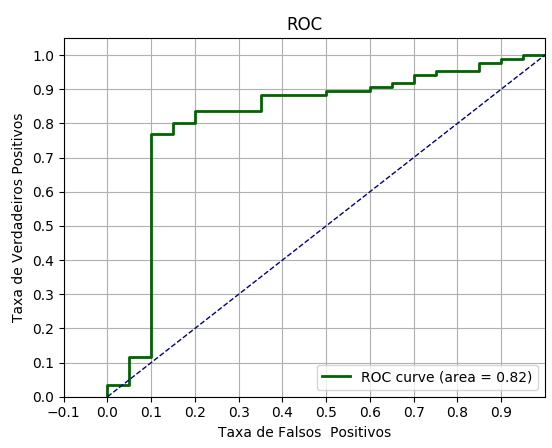
Figura 6 – Curva ROC
- Conclusão
O trabalho proposto teve como objetivo a prevenção do suicídio, visando à identificação de textos com ideações suicidas através do estudo e aplicação de técnicas de mineração de texto.
A etapa inicial consistiu na coleta de dados para a análise, seguida do pré-processamento e limpeza dos mesmos com a finalidade de aumentar qualidade para aplicação dos algoritmos de aprendizagem de máquina. Foram utilizados dois algoritmos: Doc2Vec e Regressão Logística. O Doc2Vec foi utilizado para a criação da representação vetorial e melhora na dimensionalidade dos dados. Já o algoritmo Regressão Logística foi utilizado para classificação dos textos em “Suicida” e “Não Suicida”. A combinação dos dois algoritmos apresentou uma performance considerável, mostrou uma taxa de acerto de 0.82.
Considerando os resultados obtidos, pode-se concluir que o classificador gerado é uma possível ferramenta para a prevenção do suicídio, de modo que é capaz de identificar textos com ideações suicidas.
Como trabalho futuro, pretende-se a incorporação desse classificador às redes sociais para análises automáticas de textos postados pelos usuários destas, assim como a produção de um local na WEB onde possibilitará a realização de consultas, a fim de identificar as ideações suicidas por familiares e amigos de vítimas em potencial.
O código deste projeto está disponível no GitHub, serviço de hospedagem e versionamento de códigos fonte [27].
Referências
Organização Pan-Americana da Saúde/Organização Mundial da Saúde (Ed.). “Suicídio é grave problema de saúde pública e sua prevenção deve ser prioridade”, afirma OPAS/OMS. 2018. Disponível em: https://www.paho.org/bra/index.php?option=com_content&view=article&id=5674:suicidio-e-grave-problema. Acesso em: 25 ago. 2018.
Organização Pan-Americana da Saúde/Organização Mundial da Saúde (Org.). Folha informativa – Suicídio. 2018. Disponível em: https://www.paho.org/bra/index.php?option=com_content&view=article&id=5671:folha-informativa-suicidio&Itemid=839. Acesso em: 14 nov. 2018.
Ministério da Saúde (Org.). SETEMBRO AMARELO: Brasília: Ministério da Saúde, 2017. 34 slides, color.
BOTEGA, Neury José; WERLANG, Blanca Susana Guevara; CAIS, Carlos Filinto da Silva; Macedo, Mônica Medeiros Kother. Prevenção do comportamento suicida. Psico, Porto Alegre, v. 37, n. 3, p.213-220, set. 2006
POSVENÇÃO: uma nova perspectiva para o suicídio. Salvador: Revista Brasileira de Psicologia, 2015
SAWHNEY, Ramit; MANCHANDA, Prachi; SINGH, Raj; AGGARWAL, Swat. Proceedings of ACL 2018, Student Research Workshop , pages 91–98 Melbourne, Australia, July 15 – 20, 2018.c 2018 Association for Computational Linguistics 91 A Computational Approach to Feature Extraction for Identification of Suicidal Ideation in Tweets. Computational Linguistics. Melbourne, p. 91-98. jul. 2018
CARVALHO FILHO, JosÉ Adail. MINERAÇÃO DE TEXTOS: ANÁLISE DE SENTIMENTO UTILIZANDO TWEETS REFERENTES À COPA DO MUNDO 2014. 2014. 46 f. TCC (Graduação) – Curso de Bacharelado em Engenharia de Software, Universidade Federal do CearÁ Campus QuixadÁ, QuixadÁ, 2014.
LE, Quoc; MIKOLOV, Tomas. Distributed Representations of Sentences and Documents. Roceedings Of The 31st International Conference On Machine Learning. Beijing, p. 1-9. maio 2014.
AGUIAR, Raul Freire; PRATI, Ronaldo Cristiano. Incorporação de representação vetorial distribuída de palavras e parágrafos na classificação de SMS SPAM. Universidade Federal do Abc. Santo André, Sp, p. 1-9. nov. 2015
MORAIS, Edison Andrade Martins; AMBRÓSIO, Ana Paula L.. Mineração de Textos. Goiás: Instituto de Informática Universidade Federal de Goiás, 2007.
PEZZINI, Anderson. MINERAÇÃO DE TEXTOS: CONCEITO, PROCESSO E APLICAÇÕES. Revista Eletrônica do Alto Vale do Itajaí, [s.l.], v. 5, n. 8, p.058-061, 15 fev. 2017. Universidade do Estado de Santa Catarina. http://dx.doi.org/10.5965/2316419005082016058.
ARANHA, Christian Nunes. Uma Abordagem de Pré Processamento Automático para Mineração de Textos em Português:: Sob o Enfoque da Inteligência Computacional. 2007. 144 f. Tese (Doutorado) – Curso de Pós-graduação em Engenharia Elétrica, Pontifícia Universidade Católica do Rio de Janeiro, Rio de Janeiro, 2007.
COLOMBO, Gualtiero B.; BURNAP, Pete; HODOROG, Andrei; SCOURFIELD,Jonathan . Analysing the connectivity and communication of suicidal users on twitter. Computer Communications. United Kingdom, p. 291-300. jul. 2015.
LOPER, Edward; KLEIN, Ewan; BIRD, Steven. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. 2015. Disponível em: <https://www.nltk.org/book/>. Acesso em: 14 nov. 2018.
CARRILHO JUNIOR, João Ribeiro. Desenvolvimento de uma Metodologia para Mineração de Textos. 2007. 96 f. Dissertação (Mestrado) – Curso de Pós-graduação em Engenharia Elétrica, Pontifícia Universidade Católica do Rio de Janeiro, Rio de Janeiro, 2007.
COELHO, Alexandre Ramos. Stemming para a língua portuguesa: estudo, análise e melhoria do algoritmo RSLP. 2007. 69 f. TCC (Graduação) – Curso de CiÊncia da ComputaÇÃo, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2007
SCIKIT-LEARN: Machine Learning in Python. Machine Learning in Python. Disponível em: <https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html>. Acesso em: 03 nov. 2018.
TEXTOS Tristes sobre Suicídio. Disponível em: <https://www.pensador.com/textos_tristes_sobre_suicidio/>. Acesso em: 16 nov. 2018.
SILVA, Marcimedes Martins da. Suicídio: Trama da Comunicação. 1992. 132 f. Dissertação (Mestrado) – Curso de Pós-graduação em Psicologia Social, Pontifícia Universidade Católica de São Paulo, São Paulo, 1992
ESTAS 5 NOTAS DE SUICÍDIO SÃO BASTANTE CHOCANTES. 2013. Disponível em: <www.megacurioso.com.br/comportamento/39956-estas-5-notas-de-suicidio-sao-bastante-chocantes>. Acesso em: 16 nov. 2018.
7 FAMOSOS QUE DEIXARAM CARTAS DE SUICÍDIO EMOCIONANTES. 2015. Disponível em: <www.fatosdesconhecidos.com.br/7-famosos-que-deixaram-cartas-de-suicidio-emocionantes/>. Acesso em: 16 nov. 2018
MÃE de jovem suicida conta sua versão do fato e divulga carta deixada pelo filho. 2011. Disponível em: <www.i7noticias.com/paraguacu/noticia/2402/mae-de-jovem-suicida-conta-sua-versao-do-fato-e-divulga-carta-deixada-pelo-filho>. Acesso em: 16 nov. 2018.
103 frases curtas para atualizar o seu status no Facebook. 2018. Disponível em: <https://www.42frases.com.br/frases-curtas-facebook/>. Acesso em: 16 nov. 2018.
50 FRASES de felicidade para transformar sua visão do que é ser feliz. 2018. Disponível em: <https://awebic.com/humor/frases-felicidade/>. Acesso em: 16 nov. 2018.
99 FRASES motivacionais de empreendedores de sucesso. 2018. Disponível em: <https://www.agendor.com.br/blog/frases-motivacionais-de-empreendedores-de-sucesso/>. Acesso em: 16 nov. 2018.
RADIM REHUREK (Org.). Models.doc2vec: Doc2vec paragraph embeddings. Disponível em: <https://radimrehurek.com/gensim/models/doc2vec.html>. Acesso em: 16 nov. 2018.
SANTOS, Elizangela de Freitas dos. TCC – Mineração de Texto. 2018. Disponível em: <https://github.com/liz-freitas/tcc-mineracao-de-texto>. Acesso em: 18 nov. 2018.



